Govern wherever data lives.
The intelligence layer between your AI and your data - semantics, context and governance, in one. On every tool call, across every system, with a verdict you can show.
Semantic governance without centralisation.
SEAM doesn't force your data into a new silo. It acts as the intelligent proxy that translates natural language intent into governed execution - wherever your data already lives.
No replatforming
SEAM works whether you have a warehouse, are building one, have one that needs rescuing or have decided you don't need one. It governs whatever you have, wherever it lives.
Existing investment protected
If you've already invested in a warehouse and a semantic layer, none of that is wasted. SEAM governs it alongside everything else - making that investment pay off in an agentic world.
Definitions as infrastructure
Version-controlled, reviewed, tested and owned. The same rigour you apply to code, applied to the meaning of your data. Governance that improves over time, not documentation that rots.
SEAM governs structured and unstructured sources - but honestly about the difference. For databases and warehouses, governance is deterministic: every metric resolves to a validated query, every answer traces to a governed definition. For unstructured sources - Slack channels, documents, emails, meeting transcripts - SEAM applies source hierarchy and context weighting, ensuring agents know which sources to trust and how to prioritise conflicting information. Both are governed. The mechanisms are different. Having both in one layer is a capability no warehouse has ever offered.
What we mean by it
The intelligence layer is three things in one.
Semantics - what revenue, active customer and churn actually mean. (Semantic-layer territory: Cube, dbt-semantic, Looker.)
Context - which Customer that metric resolves to, across Billing, CRM and Warehouse, with which fallbacks. (The cross-system tribal knowledge semantic layers weren't built for.)
Governance - every call (read or write) matched to a definition, every answer with a source, every action with a record, every verdict logged. (Metadata catalogues cover part of this; SEAM does it on every tool call.)
A semantic layer is necessary, not sufficient. A context layer or catalogue gets you halfway. The intelligence layer is all three together - and that's what SEAM is.
Claude
2,471 active customers as of today - payments in the last 90 days plus active subs, deduped on customer_id.
verified
Verified through SEAM · crm_billing canonical · audit logged
"governed": true,
"metric": "active_customer",
"definition": "Payment in last 90 days OR active sub",
"source": "crm_billing",
"entity_key": "customer_id",
"temporal_note": "Updated 2026-03-15: 60d → 90d window",
"confidence": "high",
"governance_status": "approved",
"audit_id": "resolve-2026-04-29-546be0"
}
In the SEAM bench, the governed agent was correct on 100% of entity-routing tasks; the ungoverned baseline was correct on 50%. Read the full report →
More than a glossary. The full reasoning context.
SEAM encodes everything an AI agent needs to give correct, consistent, auditable answers across your organisation.
Metric definitions
What "revenue", "active customer" and "churn rate" actually mean here. In this business. With these edge cases. Context-specific variants for different teams.
Source hierarchy
When two systems disagree, which one wins and why. When the warehouse has a modelled figure and a live system has a different one, which takes precedence for which question.
Entity resolution
How a record in one system maps to a record in another. The connective tissue between systems that were never designed to talk to each other.
Business logic
Fiscal year boundaries, attribution models, segmentation rules. The stuff that lives in someone's head until they leave the company.
Temporal context
When definitions changed, which version applies to which period. Because "active customer" might have meant something different before the pricing restructure.
Audit trails
Every governed answer carries a trace: which definitions were applied, which sources were queried, which resolution path was taken. Full explainability.
Made for our stack. Bends to yours.
We built SEAM Runtime for our own work first - these are the connections governing Measurelab's own data, day-to-day. New connectors are added to the catalog daily, and any MCP-compliant source can be wired up beyond it. Every call governed by your definitions - read or write - every answer and every action named in your Audit Log alongside its verdict.
Data & analytics
- Google BigQuery
- Google Cloud
- Google Analytics
- Google Tag Manager
- PostHog
- monitoring Amplitude
- analytics Mixpanel
- trending_up Ahrefs
- search SEMrush
Project management
- Atlassian (Jira / Confluence)
- Notion
- view_kanban Linear
- calendar_month Monday.com
- check_circle Asana
- record_voice_over Fathom
Communication & docs
- Slack
- support_agent Intercom
- Google Workspace
- Google Drive
- description Slab
- GitHub
Sales & ops
- HubSpot
- credit_card Stripe
- business_center OpsHub Built by us
- schedule Harvest
- groups CharlieHR
Want to see how this would map to your stack? Tell us what's in it and we'll plan the connectors with you. Runtime proxies any MCP-compliant source through the same governance layer.
What you actually use day-to-day.
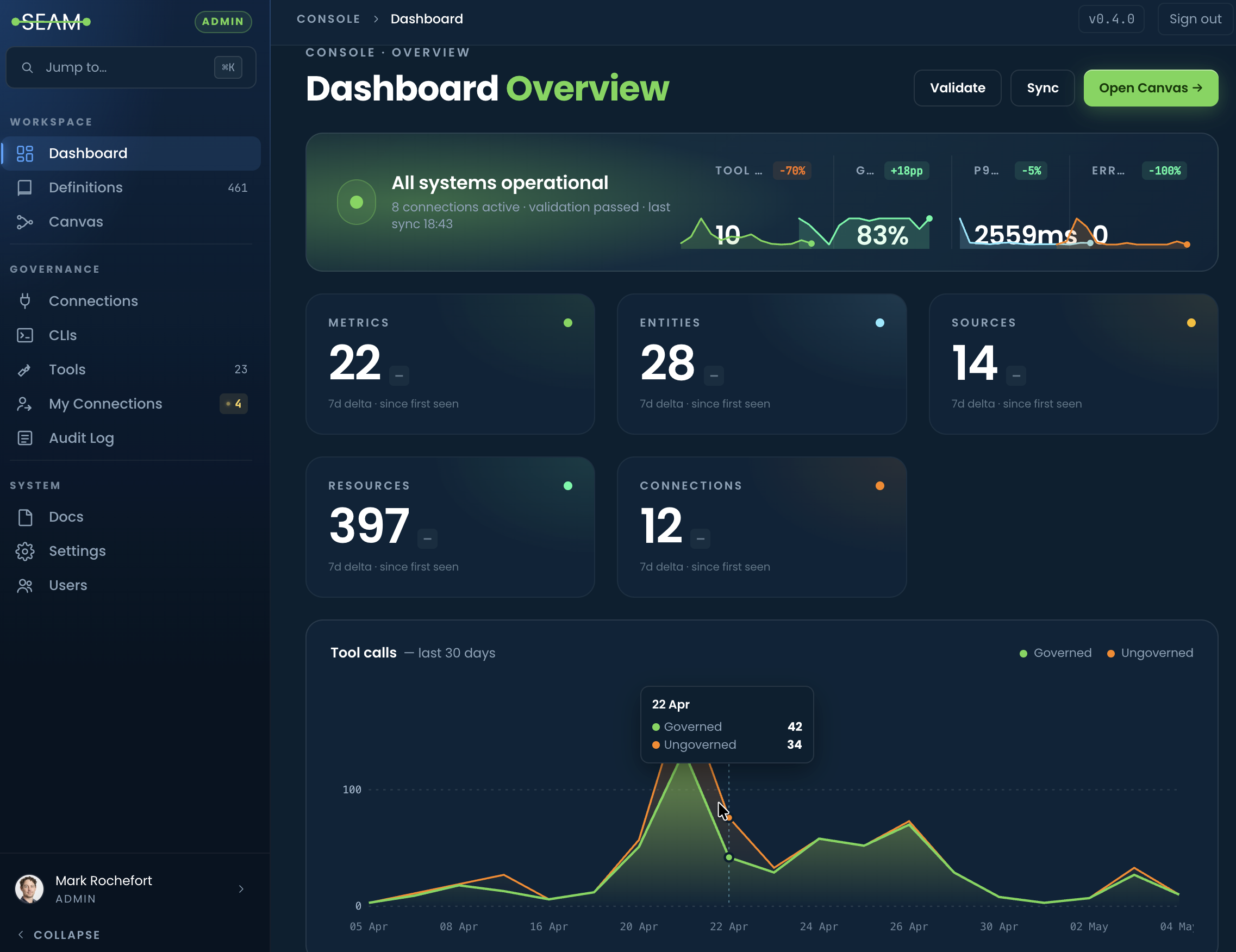
SEAM Runtime is accessible as a single online Console - one place for browsing the map, editing definitions, watching the audit trail and managing connections.
Definitions
Four types, one CRUD surface, managed via Git:
- Metrics - canonical source plus fallbacks
- Entities - types (Client, Invoice) and instances (your actual clients) with cross-system resolution
- Resources - data tables with schema
- Connections - transport, auth, governance metadata per source
Each carries owner, review cadence and tags. SEAM warns when a review goes overdue.
Canvas
The Lineage view. Every metric, entity, resource and connection on one zoomable graph. Filter by definition type, search across the model, click through to edit. Built on React Flow.
Audit Log
Every tool call, every verdict:
- Governed - matched a definition
- Resource-gap - source matched, no resource
- Ungoverned - no match
Live ring buffer in the Console. Full history in BigQuery.
Plus a Dashboard for at-a-glance health, Workspaces for editing definitions in your own private workspace and admin pages for connections, tools and users.
How you get live.
Most teams follow the same arc. Discovery, first definitions, first governed call, trail starts paying. By the end of week two, your agents are resolving through SEAM and your Audit Log has a verdict for every call.
Map what you actually use.
Run seam init from the CLI to scaffold a model yourself, or sit down with us in a workshop. Either way the goal is the same: capture your real metrics, entities and sources - the ones you use today, not the aspirational ones.
Canonical sources, ranked fallbacks.
Each metric gets a canonical source and ranked fallbacks. Each entity gets cross-system identifiers and resolution rules. Built with you in the Console, versioned in your Git repository as YAML.
Same prompt, same answer.
Your agents start resolving through SEAM. The Audit Log fills with verdicts - governed, resource-gap or ungoverned - one row per call.
Audit by default, not by effort.
Every answer and every action traceable to a definition. Every drift visible in the log. New metrics inherit the same governance from day one. The audit log records what was asked, what was answered and what was changed - one trail.
Steps 1-2 can be self-served via the CLI or done with us in a workshop - the open-source Framework produces the same governed YAML either way. Steps 3-4 are the Measurelab-managed Runtime in front of your agents in production.
Canvas: the Lineage view of your intelligence layer.
In the SEAM Console, Canvas is the Lineage page - every metric, entity, resource and connection on one zoomable graph. Scaffold the model yourself from the CLI or kick off in a workshop with us; from then on Canvas is the everyday surface for adding, refining and reviewing definitions. Lives in your Git repository, evolves with your business and feeds SEAM Runtime.
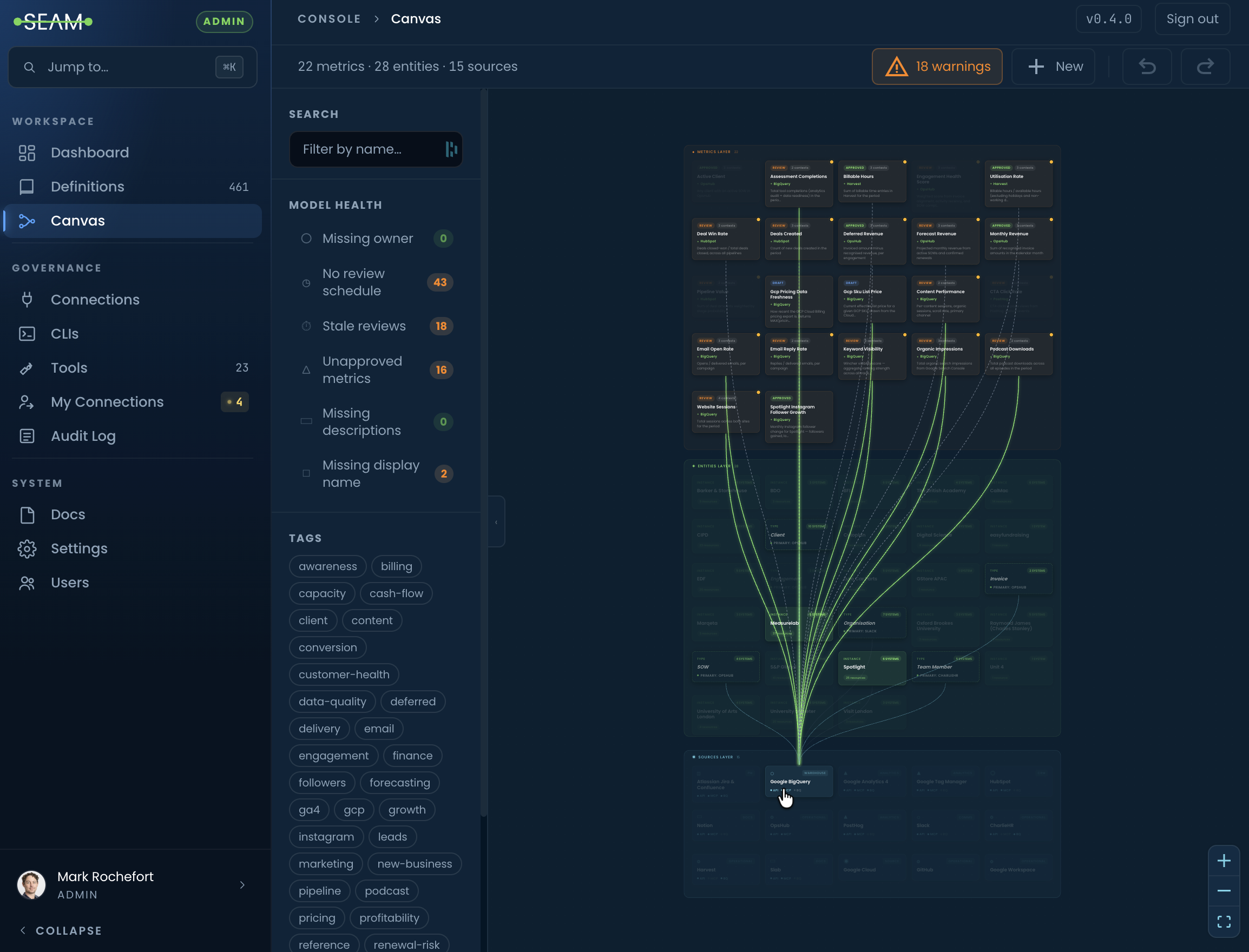
Canvas inside the SEAM Console. The full model on one surface - 22 metrics, 28 entities, 15 sources - with green lineage edges tracing from the selected source (Google BigQuery, bottom) up through the entities it touches and the metrics it feeds. Model Health flags surface stale reviews and unapproved metrics; Tags filter the view by business domain. This is Measurelab's own canvas, dogfooded daily.
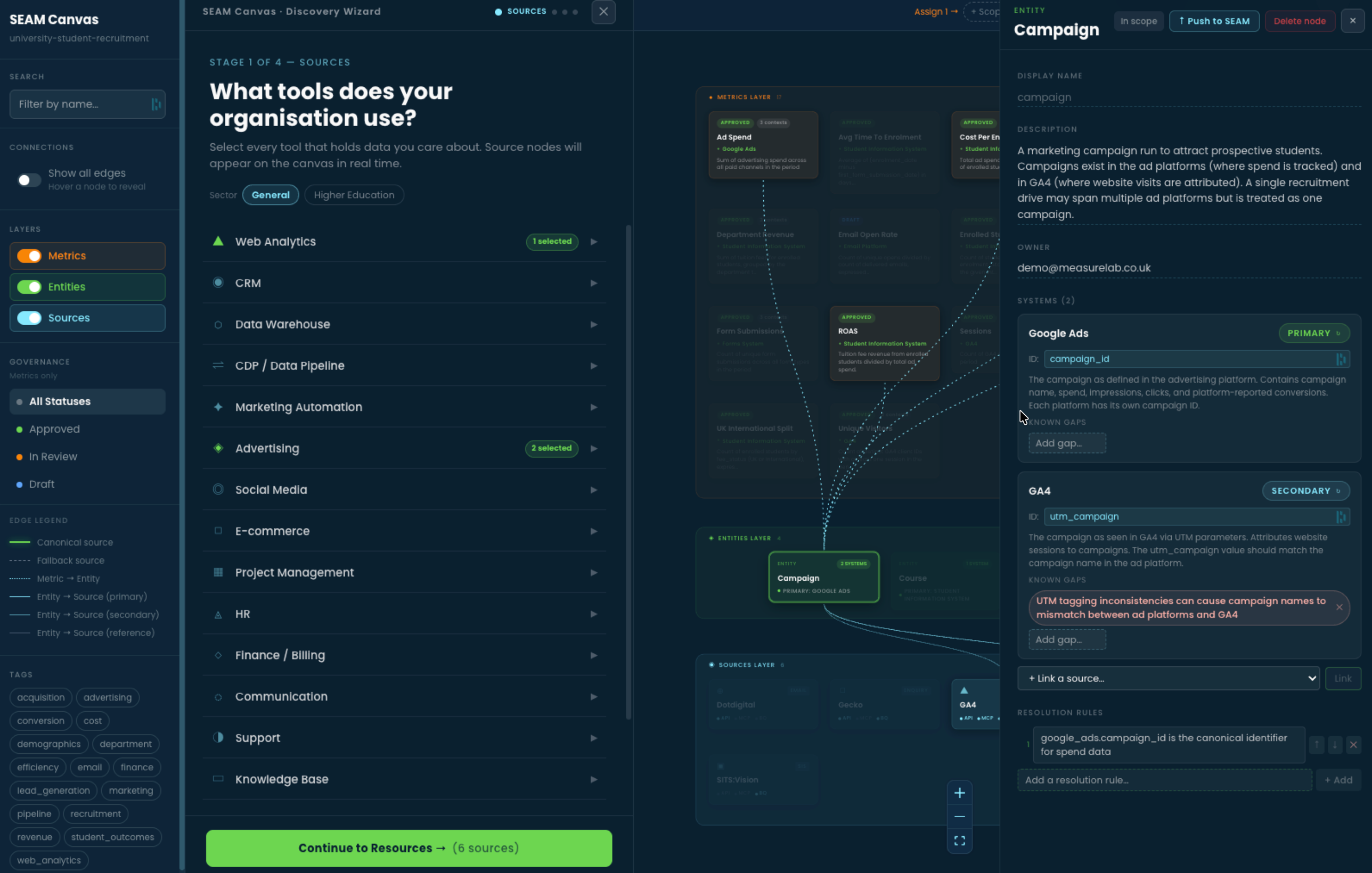
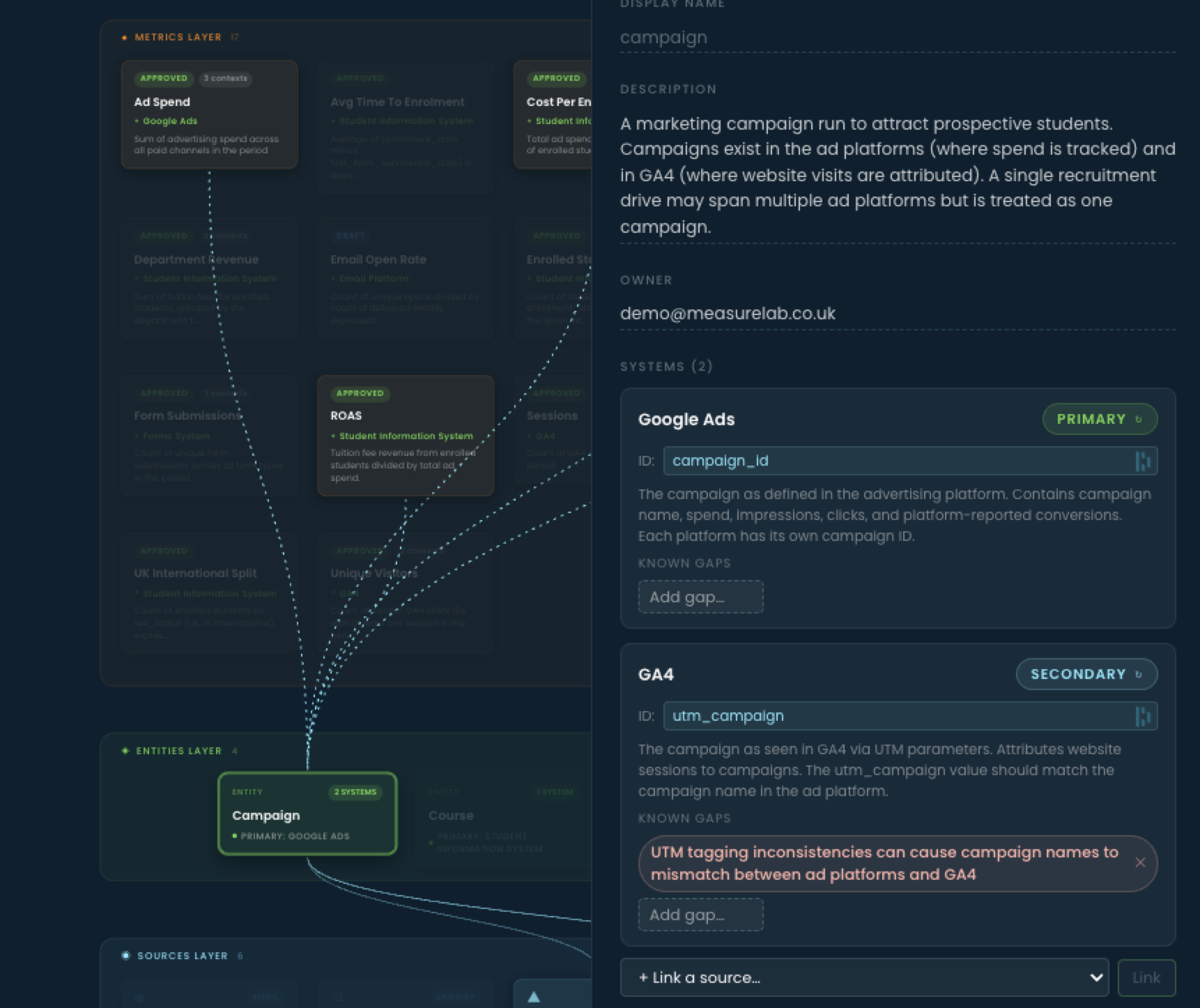
The Campaign entity panel. Two systems hold campaign data - Google Ads (primary, using campaign_id) and Google Analytics (secondary, using utm_campaign). Both systems are captured in one governed entity. Known gaps are recorded explicitly: here, UTM tagging inconsistencies between ad platforms and Google Analytics. Resolution rules say which identifier wins for which question.
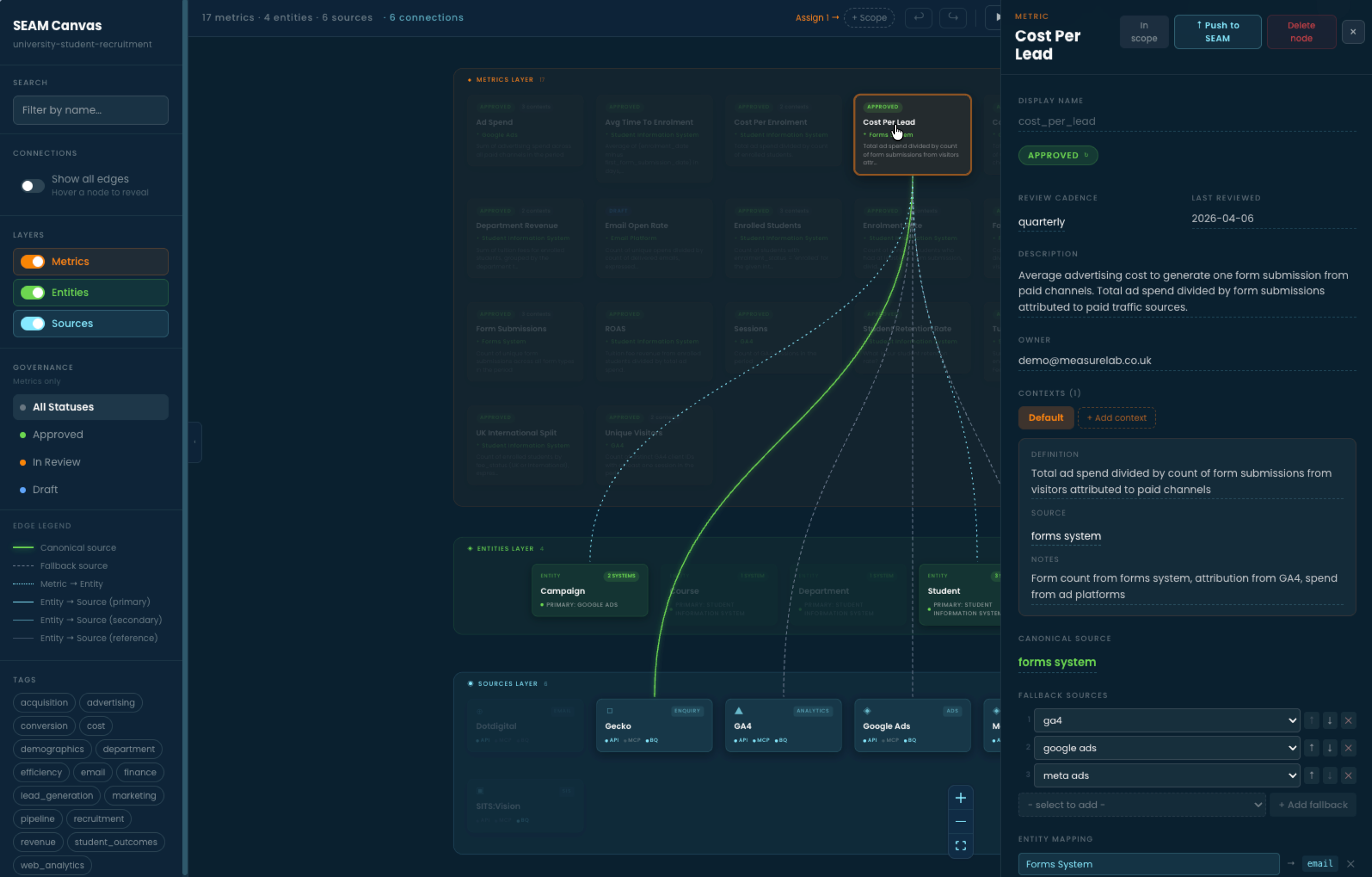
The Cost Per Lead metric panel. Every governed metric carries its definition, its owner, its review cadence, its canonical source and an ordered list of fallback sources for when the canonical one fails. Here, the forms system is canonical; Google Analytics, Google Ads and Meta Ads are fallbacks in priority order. Definitions are reviewed quarterly and timestamped.
A closer view of the metrics and entities layers. Each metric card carries its status (Approved, Draft), the number of contexts it has, its canonical source and a short definition. The lineage edges trace every metric down through the entities it measures to the sources it trusts. When an agent resolves a question, this is the graph it walks. When a definition changes, this is the graph that shows what the change affects.
Canvas is one of two ways to author definitions. Engineering teams can also write YAML directly in code, validated via the SEAM CLI and versioned in Git. Both paths produce the same governed output and both feed into the architecture below.
The SEAM engine architecture
Definition files (YAML)
The source of truth. Version-controlled YAML schemas for the four definition types: metrics, entities, resources, connections.
mrr:
sql: "sum(revenue)"
filters: ["status='active'"]
Compiler / validator
Validates every definition against its schema before deployment, catching errors early.
Context resolver
Intelligently maps what the agent is asking for to the right governed definition.
Runtime (MCP proxy)
Sits between your AI agents and every system they touch - intercepting, governing and auditing every tool call, read or write. Sixteen-plus pre-built source connections; any custom MCP server proxied through the same governance layer.
Audit logger
Every call tagged governed, resource-gap or ungoverned. Live in the Console; full history in BigQuery.
Author in the Console. Or in your editor.
Two peer surfaces. Both produce the same governed YAML. Both feed the same Runtime.
In the Console
Canvas as the visual map. A parsed-fields panel for clicking through definitions. A Monaco YAML editor for in-browser code edits. Used continuously by analysts, finance leads, ops managers, marketers - anyone who knows the business.
Embedded in the Runtime Console at /ui/. Included in the engagement.
In your editor
YAML in your IDE of choice, validated via the seam CLI, versioned in Git, reviewed in pull requests. Slots in alongside dbt, Dataform or any IaC pipeline.
Open source. Apache-2.0 on npm. Free to use standalone via the SEAM Framework.
"Governance trades nothing, and improves correctness."
From the SEAM bench · April 2026 · Read the full report →
Engineered query flow
User question
"What was the total ARR for enterprise customers in Q3?"
Agent intent parsing
LLM generates tool requirements based on natural language prompt.
SEAM resolution & logic binding
Proxied execution
The validated, governed query is executed against the secure endpoint.
Governed answer
Agent receives high-integrity data and provides an accurate, fully audited response.
Every definition carries a cadence.
Each metric, entity, resource and connection has an owner, a review cadence and a last-reviewed timestamp. SEAM warns when a review is due, escalates when it's overdue, and resets the clock the moment someone reviews it. The Console surfaces the lot under one Model Health filter.
monthly_revenue
Sum of recognised revenue per calendar month. Canonical source: Billing. Used by 12 reports.
Owner
finance@acme.co
Review cadence
monthly
LAST REVIEWEDtoday
LAST REVIEWED21 days ago · due in 9 days
LAST REVIEWED37 days ago · 7 days overdue
Every call, every verdict, live.
The Audit Log streams live in the Console as your agents work. Filter by verdict, user or source. Expand any row to see SEAM's governance text and the matched definition. Persisted to BigQuery for full history.
Built on open standards. Extended where they stop.
SEAM's definition format is informed by the Open Semantic Interchange (OSI) specification - the emerging vendor-neutral standard backed by Snowflake, dbt Labs, Salesforce and Databricks - and extended to cover source hierarchies and unstructured sources that OSI doesn't yet address. Your definitions are portable where the standard applies and purpose-built where it doesn't.
| Capability | OSI | SEAM |
|---|---|---|
| Metric definitions (SQL) | ✅ Core focus | ✅ Supported |
| Entity relationships | ✅ Join paths | ✅ Cross-system resolution |
| Source hierarchy | ❌ Warehouse-only | ✅ Any source, ranked |
| Unstructured sources | ❌ Not addressed | ✅ Context-weighted |
| Agent mediation | ❌ Not in scope | ✅ Core function |
| Audit trails | ❌ Not in scope | ✅ Full lineage |
| Temporal versioning | ❌ Not addressed | ✅ Definition history |
| Governance enforcement | ❌ Definitions only | ✅ Observe / Advise / Enforce |
Existing tools weren't built for this.
Data catalogues map the territory for humans browsing. Semantic layers govern queries to a warehouse. SEAM is the intelligence layer between your AI and your data - a different problem, a different layer.
"Why not Atlan, Collibra or another data catalogue?"
Data catalogues tell humans what data exists. SEAM tells agents what it means. Different problem, different layer, different price point. Use both - your catalogue maps the territory; SEAM governs the journey.
"Why not dbt's MCP server?"
dbt exposes an MCP server - it lets agents query your semantic layer. SEAM is an MCP proxy - it sits between agents and every tool call, governing what gets through. dbt gives agents access to warehouse metrics. SEAM governs the access itself, across all sources, structured and unstructured.
"How is this different from Cube?"
Cube is a powerful semantic layer for SQL-based data. It governs queries to your warehouse. SEAM governs queries to everything - warehouses, APIs, documents, Slack, email. And it does it at the agent level, not the query level. Source hierarchy, context weighting and audit trails apply whether the data is in BigQuery or a Google Doc.
Catalogues and semantic layers govern data at rest or in the warehouse. SEAM governs the agent's entire view of your organisation.
Compliance regimes for AI agents are arriving fast.
The EU AI Act, ISO 42001, GDPR's AI extensions - all of them require what SEAM produces by default:
- check_circle An inventory of agent actions
- check_circle Traceable data flows
- check_circle Behavioural drift detection
- check_circle A complete audit trail
Building this yourself is a multi-quarter project. SEAM ships it on day one of an engagement.
Use SEAM in your organisation.
SEAM has two halves. The open-source Framework is what you author your intelligence model with: install the SEAM CLI from npm to start authoring locally. The Measurelab-managed Runtime is what runs that model in front of your agents in production. Book a demo to talk through your AI agents, your data and how an engagement looks.